1. 테이블(Table)
- 데이터를 저장하는 데이터베이스의 가장 기본적인 오브젝트
- 로우(Row)
- 튜플, 인스턴스, 어커런스
- 컬럼(Column)
- 각 속성 항목에 대한 값을 저장
- 기본키(Primary Key)
- 후보키 중에서 선택한 주키
- 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성
- 외래키(Foreign Key)
- 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합
- 한 릴레이션에 속한 속성 A와 참조 릴레이션의 기본키인 B가 동일한 도메인 상에서 정의되었을 때의 속성 A를 외래키라고 함
2. 엔티티 (Entity)를 테이블로 변환
- 논리 데이터 모델에서 정의된 엔티티를 물리 데이터 모델의 테이블로 변환하는 것
- 엔티티 테이블로 변환 후 테이블 목록 정의서 작성
- 변환 시 고려사항
- 일반적으로 테이블과 엔티티 명칭을 동일하게 하는 것을 권고
- 엔티티는 주로 한글명을 사용하지만 테이블은 소스 코드의 가독성을 위해 영문명을 사용
- 메타 데이터 관리 시스템에 표준화된 용어가 있을 때는 메타에 등록된 단어를 사용하여 명명
3. 슈퍼타입 / 서브타입을 테이블로 변환
- 논리 데이터 모델에서 이용되는 형태
- 물리 데이터 모델을 설계할 때 슈퍼타입/서브타입을 테이블로 변환해야 함
1) 슈퍼타입 기준 테이블 변환
- 서브타입을 슈퍼타입에 통합하여 하나의 테이블로 만드는 것
- 서브타입에 속성이나 관계가 적을 경우에 적용하는 방법
- 하나로 통합된 테이블에는 서브타입의 모든 속성이 포함되어야 함
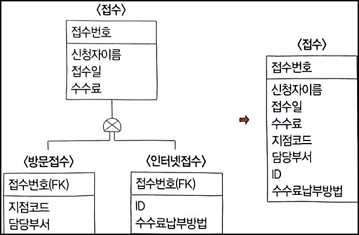
💡 서브타입의 <방문접수> 개체에 있는 '지점코드', '담당부서'와 <인터넷접수> 개체에 있는 'ID', '수수료납부방법'이 슈퍼타입인 <접수>개체에 통합되어 <접수> 테이블로 변환
- 장점
- 데이터의 액세스가 상대적으로 용이
- 뷰를 이용하여 각 서브타입만을 액세서하거나 수정
- 서브타입 구분이 없는 임의 집합에 대한 처리가 용이
- 여러 테이블을 조인하지 않아도되므로 수행속도가 빨라짐
- SQL문장 구성이 단순해짐
- 단점
- 테이블의 컬럼이 증가하므로 디스크 저장 공간이 증가
- 처리마다 서브타입에 대한 구분(TYPE)이 필요한 경우가 많이 발생
- 인덱스 크기의 증가로 인덱스의 효율이 떨어짐
2) 서브타입 기준 테이블 변환
- 슈퍼타입 속성들을 각 서브타입에 추가하여 서브타입들을 개별적인 테이블로 만드는 것
- 서브타입에 속성이나 관계가 많이 포함된 경우 적용
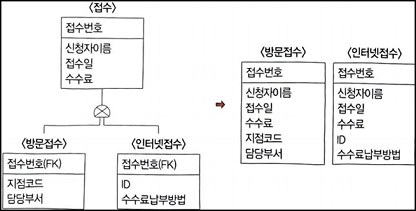
💡 슈퍼타입인 <접수> 개체에 있는 '신청자이름', '접수일', '수수로'가 서브타입인 <방문접수>개체와 <인터넷접수> 개체에 각각 추가되어 <방문접수>와 <인터넷접수>테이블로 변환
- 장점
- 각 서브타입 속성들의 선택 사양이 명확한 경우 유리
- 처리할 때마다 서브타입 유형을 구분할 필요 없음
- 여러 개의 테이블로 통합하므로 테이블당 크기가 감소하여 전체 테이블 스캔 시 유리
- 단점
- 수행속도 감소
- 복잡한 처리를 하는 SQL의 통합이 어려움
- 부분 범위에 대한 처리가 곤란
- 여러 테이블을 통합한 뷰는 조회만 가능
- UID의 유지 관리 어려움
3) 개별타입 기준 테이블 변화
- 슈퍼타입과 서브타입들을 각각의 개별적인 테이블로 변환하는 것
- 슈퍼타입과 서브타입 테이블들 사이에는 각 1:1 관계가 형성
- 개별 타입 기준 테이블로 변환을 적용하는 경우
- 전체 데이터에 대한 처리가 빈번한 경우
- 서브타입의 처리가 대부분 독립적으로 발생하는 경우
- 통합하는 테이블의 컬럼 수가 많은 경우
- 서브 타입의 컬럼 수가 많은 경우
- 트랜잭션이 주로 슈퍼타입에서 발생하는 경우
- 슈퍼타입의 처리 범위가 넓고 빈번하게 발생하여 단일 테이블 클러스터링이 필요한 경우
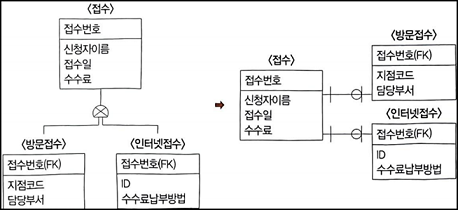
💡 슈퍼타입의 <접수> 개체와 서브타입의 <방문접수>, <인터넷접수> 개체가 각각 <접수>, <방문접수>, <인터넷접수> 테이블로 변환
- 장점
- 저장공간이 상대적으로 작음
- 슈퍼타입 또는 서브타입 각각의 테이블에 속한 정보만 조회하는 경우 문장 작성이 용이
- 단점
- 슈퍼타입 또는 서브타입의 정보를 같이 처리하면 항상 조인이 발생하여 성능이 저하됨
4. 속성을 컬럼으로 변환
- 논리 데이터 모델에서 정의한 속성을 물리 데이터 모델의 컬럼으로 변환
- 일반 속성 변환
- 속성과 컬럼은 명칭이 반드시 일치할 필요는 없으나 개발자와 사용자 간 의사소통을 위하여 가능한 표준화된 약어를 사용하여 일치시키는 것이 좋음
- 컬럼명은 SQL의 예약어 사용 금지
- 컬럼명은 SQL의 가독성을 높이기 위해 가능한 짧게 지정
- 복합 단어를 컬럼명으로 사용할 때는 미리 정의된 표준을 따름
- 테이블의 컬럼을 정의한 후 한 로우에 해당하는 샘플 데이터를 작성하여 컬럼의 정합성을 검증

💡 <사원>엔티티의 '부서번호', '이름', '주소', '전화번호', '이메일' 속성이 <사원> 테이블의 각각의 컬럼으로 변환
- Primary UID를 기본키로 변환
- 논리 데이터 모델 Primary UID는 물리데이터 모델의 기본키
- Primary UID(관계의 UID Bar)를 기본키로 변환
- 다른 엔티티와는 관계로 인해 생성된 Primary UID는 물리데이터 모델의 기본키
- Secondary(Alternate) UID를 유니크키로 변환
- 논리 모델링에서 정의된 Secondary UID 및 Alternate Key는 물리 모델에서 유니크 키
5. 관계를 외래키로 변환
- 논리 데이터 모델에서 정의된 관계는 기본키와 이를 참조하는 외래키로 변환
- 1:1 관계
- 객체 A의 기본키를 개체 B의 외래키로 추가하거나 개체 B의 기본키를 개체 A의 외래키로 추가하여 표현

- 1:M 관계
- 개체 A의 기본키를 개체 B의 외래키로 추가하여 표현하거나 별토듸 테이블로 표현

- N:M관계
- 릴레이션 A와 B의 기본키를 모두 포함한 별도의 릴레이션으로 표현
- 생성된 별로의 릴레이션을 교차 릴레이션 또는 교차 엔티티라고 함

- 1:M 순환 관계
- 개체 A에 개체 A의 기본키를 참조하는 외래키 컬럼을 추가하여 표현
- 데이터의 계층 구조를 표현하기 위해 주로 사용

6. 관리 목적의 테이블 / 컬럼 추가
- 논리 데이터 모델에는 존재하지 않으나 테이블이나 컬럼을 데이터베이스의 관리 혹은 데이터베이스를 이용하는 프로그래밍의 수행 속도를 향상시키기 위해 물리 데이터 모델에 추가
7. 데이터 타입 선택
- 논리 데이터 모델에서 정의된 논리적인 데이터 타입을 물리적인 DBMS의 물리적 특성과 성능을 고려하여 최적의 데이터 타입과 데이터 최대 길이를 선택
📖 Reference
2023 시나공 정보처리기사 필기 : 네이버 도서
네이버 도서 상세정보를 제공합니다.
search.shopping.naver.com
728x90
반응형
'Certificate > 정보처리기사' 카테고리의 다른 글
| [3과목 데이터베이스 구축] SQL 응용 - 107. ⭐ SQL (Structured Query Language) 개념 (0) | 2025.11.19 |
|---|---|
| [3과목 데이터베이스 구축] 물리 데이터베이스 설계 - 106. 물리 데이터 모델 품질 검토 (0) | 2025.11.19 |
| [3과목 데이터베이스 구축] 물리 데이터베이스 설계 - 104. ⭐ 스토리지 (0) | 2025.11.19 |
| [3과목 데이터베이스 구축] 물리 데이터베이스 설계 - 103. 데이터베이스 백업 (0) | 2025.11.19 |
| [3과목 데이터베이스 구축] 물리 데이터베이스 설계 - 102. ⭐ 데이터베이스 보안 - 접근 통제 (0) | 2025.11.18 |